|
Created by: |
SNP |
|
Client-dependent: |
No |
|
Settings as variant: |
No |
|
Support for RecycleBin: |
No |
|
Recommended for HANA pre-migration Housekeeping: |
Yes |
|
Pause/resume support: |
Yes |
Introduction
The task InfoCube Compression is part of the Business Warehouse deletion tasks.
Data loaded in the InfoCube is identified via the request IDs associated with it. However, the request ID concept can also cause the same data records to appear more than once in the F fact table. This unnecessarily increases the volume of data and reduces the performance in reporting because the system must aggregate using request IDs every time the query is executed. The compression of the InfoCube eliminates these disadvantages and brings data from different requests together into one single request. In this case, compression means to roll up the data so that each data set is only included once, therefore deleting the request information.
The compression improves the performance by removing the redundant data. The compression also reduces memory consumption by deleting request IDs associated with the data. Furthermore, it reduces the redundancy by grouping by one dimension and aggregating by cumulative key figures.
The compression reduces the number of rows in the F fact table because when the requests are compressed, all data moves from the F fact table to the E fact table. This results in accelerated loading into the F fact table, faster updating of the F fact table indexes, a shorter index rebuilding time, and faster rollups since the F fact table is the source of data for rollups.
In SNP Outboard™ Housekeeping, it is possible to compress the InfoCubes using a retention time.
1. In the main SNP Outboard™ Housekeeping menu, select Business Warehouse > Deletion Tasks > Cube Compression and click Settings.
2. Specify your desired settings. You can create new settings by entering a new ID or choose from existing settings.
Parameters are usually different for each system and are therefore not meant to be transported, rather they are set on each system separately.
For more information on settings, refer to the Creating a settings ID chapter of this user documentation.
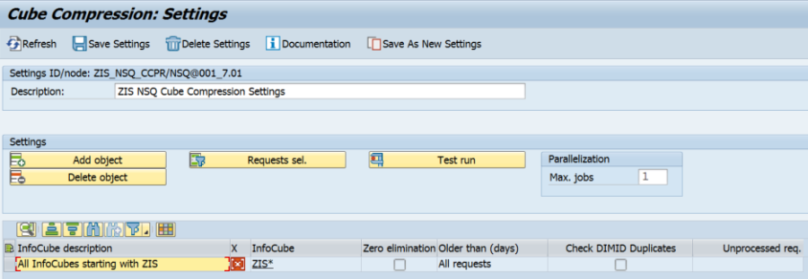
InfoCube Compression – settings group selection
You can edit the created settings group. To save your changes, click Save Settings in the taskbar.
You can click Add object to select the InfoCube(s) that you want to compress. Once you have selected them, click confirm.

InfoCube Compression – settings group selection
Icons in the X column indicate how the lines apply to the overall list of InfoCubes:
 The pattern is evaluated during the task execution, and the InfoCube is added to the overall list.
The pattern is evaluated during the task execution, and the InfoCube is added to the overall list. The pattern is evaluated during the task execution, and the InfoCube is removed from the overall list.
The pattern is evaluated during the task execution, and the InfoCube is removed from the overall list. The InfoCube is added to the overall list.
The InfoCube is added to the overall list. The InfoCube is removed from the overall list.
The InfoCube is removed from the overall list.
If the pattern is added, you can click its technical name to display an evaluation of the pattern and show the list of InfoCubes.
As an alternative to manual selection, settings generated by the Cube Compression Analysis can be used.
After selecting one or more InfoCubes, specify settings in the request selection. Here, the selection is made according to which request IDs for InfoCube compression are identified for every InfoCube within the list. Filtering restricts criteria based on the request timestamp older than X days and on parameter always keep X requests uncompressed. To limit requests, it is possible to enter the values in the following way:
-
Either “Number of unprocessed requests” or “Process data records older than X days”
-
Both limitations
-
No limitations: In this case, all requests will be compressed
Also, you can select the option Zero Elimination after InfoCube compression. See the task Zero Elimination After Compression for more details.

InfoCube Compression – Time period settings
For Oracle databases, you can check for DIMID duplicates during the execution. This basic test recognizes whether there are multiple lines that have different DIMIDs (dimension table keys) but have the same SIDs for the selected dimension table for the InfoCube specified. This can occur by using parallel loading jobs. This has nothing to do with inconsistency, however, unnecessary storage space is occupied in the database.
Since the different DIMIDs with the same SIDs are normally used in the fact tables, they cannot simply be deleted. Therefore, all of the different DIMIDS in the fact tables are replaced by one DIMID that is randomly selected from the equivalent ones.
DIMIDs that have become unnecessary are deleted. In doing so, not only are the DIMDs deleted that were released in the first part of this process, but also all of those DIMDs that are no longer used in the fact tables (including aggregates).
If you select this option for any database other than an Oracle database, it will be ignored during execution.
When an InfoCube contains indexes that can slow down the InfoCube compression, you can choose whether to drop the index before the compression itself and repair it after compression is complete. You can enable this function for DB indexes or aggregate indexes.
You can display identified request IDs by clicking Test Run.
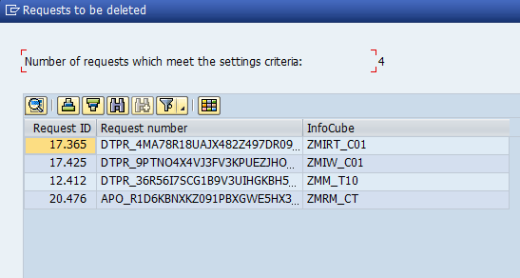
InfoCube Compression – Test run result
As the last step, you can define the maximum number of jobs that can run in parallel by using the input field Max. jobs on the right-hand side.
InfoCube Compression – Parallelization – Max. jobs
Once the settings for the InfoCube compression have been specified, you can run the created/modified settings group from the main menu. There are several options for starting the InfoCube compression. For more information, refer to the Executing and Scheduling Activities chapter of this user documentation.
You should specify the settings ID when executing/scheduling the activity.
To check the status of the run, you can go to the monitor or check the logs.
Our recommendation is to compress as soon as possible any requests for InfoCubes that are not likely to be deleted. This also applies to the compression of the aggregates. The InfoCube content is likely to be reduced in size, so DB time of queries should improve.
Note that after compression, the individual requests cannot be accessed or deleted. Therefore, you must be absolutely certain that the data loaded into the InfoCube is correct.